Каждый современный человек владеет ноутбуком, но как самому убрать возникающие...


Хранимые процедуры SQL представляют собой исполняемый программный модуль, который может храниться в в виде различных объектов. Другими словами, это объект, в котором содержатся SQL-инструкции. Эти хранимые процедуры могут быть выполнены в клиенте прикладных программ, чтобы получить хорошую производительность. Кроме того, такие объекты нередко вызываются из других сценариев или даже из какого-либо другого раздела.
Многие считают, что они похожи на процедуры различных (соответственно, кроме MS SQL). Пожалуй, это действительно так. У них есть схожие параметры, они могут выдавать схожие значения. Более того, в ряде случаев они соприкасаются. Например, они сочетаются с базами данных DDL и DML, а также с функциями пользователя (кодовое название - UDF).
В действительности же хранимые процедуры SQL обладают широким спектром преимуществ, которые выделяют их среди подобных процессов. Безопасность, вариативность программирования, продуктивность - все это привлекает пользователей, работающих с базами данных, все больше и больше. Пик популярности процедур пришелся на 2005-2010 годы, когда вышла программа от "Майкрософт" под названием «SQL Server Management Studio». С ее помощью работать с базами данных стало гораздо проще, практичнее и удобнее. Из года в год такой набирал популярность в среде программистов. Сегодня же является абсолютно привычной программой, которая для пользователей, «общающихся» с базами данных, встала наравне с «Экселем».
При вызове процедуры она моментально обрабатывается самим сервером без лишних процессов и вмешательства пользователя. После этого можно осуществлять любые удаление, исполнение, изменение. За все это отвечает DDL-оператор, который в одиночку совершает сложнейшие действия по обработке объектов. Причем все это происходит очень быстро, а сервер фактически не нагружается. Такая скорость и производительность позволяют очень быстро передавать большие объемы информации от пользователя на сервер и наоборот.
Для реализации данной технологии работы с информацией существует несколько языков программирования. К ним можно отнести, например, PL/SQL от Oracle, PSQL в системах InterBase и Firebird, а также классический «майкрософтовский» Transact-SQL. Все они предназначены для создания и выполнения хранимых процедур, что позволяет в крупных обработчиках баз использовать собственные алгоритмы. Это нужно и для того, чтобы те, кто осуществляет управление такой информацией, могли защитить все объекты от несанкционированного доступа сторонних лиц и, соответственно, создания, изменения или удаления тех или иных данных.
Эти объекты баз данных могут быть запрограммированы различными путями. Это позволяет пользователям выбирать тип используемого способа, который будет наиболее подходящим, что экономит силы и время. Кроме того, процедура сама обрабатывается, что позволяет избежать огромных временных затрат на обмен между сервером и пользователем. Также модуль можно перепрограммировать и изменить в нужное направление в абсолютно любой момент. Особенно стоит отметить скорость, с которой происходит запуск хранимой процедуры SQL: это процесс происходит быстрее иных, схожих с ним, что делает его удобным и универсальным.
Такой тип обработки информации отличается от схожих процессов тем, что он гарантирует повышенную безопасность. Это обеспечивается за счет того, что доступ других пользователей к процедурам может быть исключен целиком и полностью. Это позволит администратору проводить операции с ними самостоятельно, не опасаясь за перехват информации или несанкционированный доступ к базе данных.
Связь между хранимой процедурой SQL и клиентским приложением заключается в использовании параметров и возвращаемых значениях. Последним не обязательно передавать данные в хранимую процедуру, однако эта информация (в основном по запросу пользователя) и перерабатывается для SQL. После того как хранимая процедура завершила свою работу, она отсылает пакеты данных обратно (но, опять же, по желанию) к вызвавшему его приложению, используя различные методы, с помощью которых может быть осуществлен как вызов хранимой процедуры SQL, так и возврат, например:
Передача данных с помощью параметра типа Output;
Передача данных с помощью оператора возврата;
Передача данных с помощью оператора выбора.
А теперь разберемся, как же выглядит этот процесс изнутри.
Вы можете создать процедуру в MS SQL (Managment Studio). После того как создастся процедура, она будет перечислена в программируемый узел базы данных, в которой процедура создания выполняется оператором. Для выполнения хранимые процедуры SQL используют EXEC-процесс, который содержит имя самого объекта.
При создании процедуры ее название появляется первым, после чего производится один или несколько параметров, присвоенных ему. Параметры могут быть необязательными. После того как параметр(ы), то есть тело процедуры, будут написаны, нужно провести некоторые необходимые операции.

Дело в том, что тело может иметь локальные переменные, расположенные в ней, и эти переменные являются локальными также по отношению к процедурам. Другими словами, их можно рассматривать только внутри тела процедуры Microsoft SQL Server. Хранимые процедуры в таком случае считаются локальными.
Таким образом, чтобы создать процедуру, нам нужно имя процедуры и, по меньшей мере, один параметр в качестве тела процедуры. Обратите внимание, что отличным вариантом в таком случае является создание и выполнение процедуры с именем схемы в классификаторе.
Тело процедуры может иметь любой вид из например, такие как создание таблицы, вставки одного или нескольких строк таблицы, установление типа и характера базы данных и так далее. Тем не менее тело процедуры ограничивает выполнение некоторых операций в нем. Некоторые из важных ограничений перечислены ниже:
Тело не должно создавать какой-либо другой хранимой процедуры;
Тело не должно создать ложное представление об объекте;
Тело не должно создавать никаких триггеров.
Вы можете сделать переменные локальными для тела процедуры, и тогда они будут находиться исключительно внутри тела процедуры. Хорошей практикой является создание переменных в начале тела хранимой процедуры. Но также вы можете устанавливать переменные в любом месте в теле данного объекта.
Иногда можно заметить, что несколько переменных установлены в одной строке, и каждый переменный параметр отделяется запятой. Также обратите внимание, что переменная имеет префикс @. В теле процедуры вы можете установить переменную, куда вы хотите. К примеру, переменная @NAME1 может объявлена ближе к концу тела процедуры. Для того чтобы присвоить значение объявленной переменной используется набор личных данных. В отличие от ситуации, когда объявлено более одной переменной в одной строке, в такой ситуации используется только один набор личных данных.
Часто пользователи задают вопрос: «Как назначить несколько значений в одном операторе в теле процедуры?» Что ж. Вопрос интересный, но сделать это гораздо проще, чем вы думаете. Ответ: с помощью таких пар, как «Select Var = значение». Вы можете использовать эти пары, разделяя их запятой.
В самых различных примерах люди показывают создание простой хранимой процедуры и выполнение ее. Однако процедура может принимать такие параметры, что вызывающий ее процесс будет иметь значения, близкие к нему (но не всегда). Если они совпадают, то внутри тела начинаются соответствующие процессы. Например, если создать процедуру, которая будет принимать город и регион от вызывающего абонента и возвращать данные о том, сколько авторов относятся к соответствующим городу и региону. Процедура будет запрашивать таблицы авторов базы данных, к примеру, Pubs, для выполнения этого подсчета авторов. Чтобы получить эти базы данных, к примеру, Google загружает сценарий SQL со страницы SQL2005.

В предыдущем примере процедура принимает два параметра, которые на английском языке условно будут называться @State и @City. Тип данных соответствует типу, определенному в приложении. Тело процедуры имеет внутренние переменные @TotalAuthors (всего авторов), и эта переменная используется для отображения их количества. Далее появляется раздел выбора запроса, который все подсчитывает. Наконец, подсчитанное значение выводится в окне вывода с помощью оператора печати.
Есть два способа выполнения процедуры. Первый путь показывает, передавая параметры, как разделенный запятыми список выполняется после имени процедуры. Допустим, мы имеем два значения (как в предыдущем примере). Эти значения собираются с помощью переменных параметров процедуры @State и @City. В этом способе передачи параметров важен порядок. Такой метод называется порядковая передача аргументов. Во втором способе параметры уже непосредственно назначены, и в этом случае порядок не важен. Этот второй метод известен как передача именованных аргументов.
Процедура может несколько отклоняться от типичной. Все так же, как и в предыдущем примере, но только здесь параметры сдвигаются. То есть параметр @City хранится первым, а @State хранится рядом со значением по умолчанию. Параметр по умолчанию выделяется обычно отдельно. Хранимые процедуры SQL проходят как просто параметры. В этом случае, при условии, параметр «UT» заменяет значение по умолчанию «СА». Во втором исполнении проходит только одно значение аргумента для параметра @City, и параметр @State принимает значение по умолчанию «СА». Опытные программисты советуют, чтобы все переменные по умолчанию располагались ближе к концу списка параметров. В противном случае исполнение не представляется возможным, и тогда вы должны работать с передачей именованных аргументов, что дольше и сложнее.

Существует три важных способа отправки данных в вызванной хранимой процедуре. Они перечислены ниже:
Возврат значения хранимой процедуры;
Выход параметра хранимых процедур;
Выбор одной из хранимых процедур.
В этой методике процедура присваивает значение локальной переменной и возвращает его. Процедура может также непосредственно возвращать постоянное значение. В следующем примере, мы создали процедуру, которая возвращает общее число авторов. Если сравнить эту процедуру с предыдущими, вы можете увидеть, что значение для печати заменяется обратным.
Теперь давайте посмотрим, как выполнить процедуру и вывести значение, возвращаемое ей. Выполнение процедуры требует установления переменной и печати, которая проводится после всего этого процесса. Обратите внимание, что вместо оператора печати вы можете использовать Select-оператор, например, Select @RetValue, а также OutputValue.
Ответное значение может быть использовано для возврата одной переменной, что мы и видели в предыдущем примере. Использование параметра Output позволяет процедуре отправить одно или несколько значений переменных для вызывающей стороны. Выходной параметр обозначается как раз-таки этим ключевым словом «Output» при создании процедуры. Если параметр задан в качестве выходного параметра, то объект процедуры должен присвоить ему значение. Хранимые процедуры SQL, примеры которых можно увидеть ниже, в таком случае возвращаются с итоговой информацией.

В нашем примере будет два выходных имени: @TotalAuthors и @TotalNoContract. Они указываются в списке параметров. Эти переменные присваивают значения внутри тела процедуры. Когда мы используем выходные параметры, вызывающий абонент может видеть значение, установленное внутри тела процедуры.
Кроме того, в предыдущем сценарии две переменные объявляются, чтобы увидеть значения, которые установливают хранимые процедуры MS SQL Server в выходном параметре. Тогда процедура выполняется путем подачи нормального значения параметра «CA». Следующие параметры являются выходными и, следовательно, объявленные переменные передаются в установленном порядке. Обратите внимание, что при прохождении переменных выходное ключевое слово также задается здесь. После того, как процедура выполнена успешно, значения, возвращаемые с помощью выходных параметров, выводятся на окно сообщений.
Эта техника используется для возврата набора значений в виде таблицы данных (RecordSet) к вызывающей хранимой процедуре. В этом примере SQL хранимая процедура с параметрами @AuthID запрашивает таблицу «Авторы» путем фильтрации возвращаемых записей с помощью этого параметра @AuthId. Оператор Select решает, что должно быть возвращено вызывающему хранимой процедуры. При выполнении хранимой процедуры AuthId передается обратно. Такая процедура здесь всегда возвращает только одну запись или же вообще ни одной. Но хранимая процедура не имеет каких-либо ограничений на возвращение более одной записи. Нередко можно встретить примеры, в которых возвращение данных с использованием избранных параметров с участием вычисленных переменных происходит путем предоставления нескольких итоговых значений.

Хранимая процедура является довольно серьезным программным модулем, возвращающим или передающим, а также устанавливающим необходимые переменные благодаря клиентскому приложению. Поскольку хранимая процедура выполняется на сервере сама, обмена данными в огромных объемах между сервером и клиентским приложением (для некоторых вычислений) можно избежать. Это позволяет снижать нагрузки на сервера SQL, что, конечно же, идет на руку их держателям. Одним из подвидов являются хранимые процедуры T SQL, однако их изучение необходимо тем, кто занимается созданием внушительных баз данных. Также существует большое, даже огромное количество нюансов, которые могут быть полезны при изучении хранимых процедур, однако это нужно больше для тех, кто планирует плотно заняться программированием, в том числе профессионально.
хранимой процедуры возможен, только если он осуществляется в контексте той базы данных , где находится процедура.В SQL Server имеется несколько типов хранимых процедур .
Создание хранимой процедуры предполагает решение следующих задач:
Создание новой и изменение имеющейся хранимой процедуры осуществляется с помощью следующей команды:
<определение_процедуры>::= {CREATE | ALTER } имя_процедуры [;номер] [{@имя_параметра тип_данных } [=default] ][,...n] AS sql_оператор [...n]
Рассмотрим параметры данной команды.
Используя префиксы sp_ , # , ## , создаваемую процедуру можно определить в качестве системной или временной. Как видно из синтаксиса команды, не допускается указывать имя владельца, которому будет принадлежать создаваемая процедура, а также имя базы данных, где она должна быть размещена. Таким образом, чтобы разместить создаваемую хранимую процедуру в конкретной базе данных, необходимо выполнить команду CREATE PROCEDURE в контексте этой базы данных. При обращении из тела хранимой процедуры к объектам той же базы данных можно использовать укороченные имена, т. е. без указания имени базы данных. Когда же требуется обратиться к объектам, расположенным в других базах данных, указание имени базы данных обязательно.
Номер в имени – это идентификационный номер хранимой процедуры , однозначно определяющий ее в группе процедур. Для удобства управления процедурами логически однотипные хранимые процедуры можно группировать, присваивая им одинаковые имена, но разные идентификационные номера.
Для передачи входных и выходных данных в создаваемой хранимой процедуре могут использоваться параметры , имена которых, как и имена локальных переменных, должны начинаться с символа @ . В одной хранимой процедуре можно задать множество параметров , разделенных запятыми. В теле процедуры не должны применяться локальные переменные, чьи имена совпадают с именами параметров этой процедуры.
Для определения типа данных, который будет иметь соответствующий параметр хранимой процедуры , годятся любые типы данных SQL, включая определенные пользователем. Однако тип данных CURSOR может быть использован только как выходной параметр хранимой процедуры , т.е. с указанием ключевого слова OUTPUT .
Наличие ключевого слова OUTPUT означает, что соответствующий параметр предназначен для возвращения данных из хранимой процедуры . Однако это вовсе не означает, что параметр не подходит для передачи значений в хранимую процедуру . Указание ключевого слова OUTPUT предписывает серверу при выходе из хранимой процедуры присвоить текущее значение параметра локальной переменной, которая была указана при вызове процедуры в качестве значения параметра . Отметим, что при указании ключевого слова OUTPUT значение соответствующего параметра при вызове процедуры может быть задано только с помощью локальной переменной. Не разрешается использование любых выражений или констант, допустимое для обычных параметров .
Ключевое слово VARYING применяется совместно с
Хранимая процедура (Stored Procedure) это набор команд, хранимый на сервере и выполняемый как единое целое. Хранимые процедуры являются механизмом, с помощью которого можно создавать подпрограммы, работающие на сервере и управляемые его процессами. Подобные подпрограммы могут быть активизированы вызывающим их приложением. Кроме того, они могут быть вызваны правилами, поддерживающими целостность данных, или триггерами.
Хранимые процедуры могут возвращать значения. В процедуре можно выполнять сравнение вводимых пользователем значений с заранее установленной в системе информацией. Хранимые процедуры применяют в работе мощные аппаратные решения SQL Server. Они ориентированы на базы данных и тесно взаимодействуют с оптимизатором SQL Server. Это позволяет получить высокую производительность при обработке данных.
В хранимые процедуры можно передавать значения и получать от них результаты работы, причем не обязательно имеющие отношение к рабочей таблице. Хранимая процедура может вычислить результаты в процессе работы.
Хранимые процедуры бывают двух типов: обычные и расширенные . Обычные хранимые процедуры представляют собой набор команд на Transact-SQL, в то время как расширенные хранимые процедуры представлены в виде динамических библиотек (DLL). Такие процедуры, в отличие от обычных, имеют префикс xp_ . Сервер имеет стандартный набор расширенных процедур, но пользователи могут писать и свои процедуры на любом языке программирования. Главное при этом использовать интерфейс программирования SQL Server Open Data Services API . Расширенные хранимые процедуры могут находиться только в базе данных Master .
Обычные хранимые процедуры также можно разделить на два типа: системные и пользовательские . Системные процедуры это стандартные процедуры, служащие для работы сервера; пользовательские любые процедуры, созданные пользователем.
В самом общем случае хранимые процедуры обладают следующими преимуществами:
Хотя язык SQL определен как непроцедурный, в SQL Server применяются ключевые слова, связанные с управлением ходом выполнения процедур. Такие ключевые слова используются при создании процедур, которые можно сохранять для последующего выполнения. Хранимые процедуры могут быть применены вместо программ, созданных с помощью стандартных языков программирования (например, С или Visual Basic) и выполняющих операции в базе данных SQL Server.
Хранимые процедуры компилируются при первом выполнении и сохраняются в системной таблице текущей базы данных. При компилировании они оптимизируются. При этом выбирается самый лучший способ доступа к информации таблицы. Подобная оптимизация учитывает реальное положение данных в таблице, доступные индексы, загрузку таблицы и т. д.
Откомпилированные хранимые процедуры могут значительно улучшить производительность системы. Стоит, однако, отметить, что статистика данных с момента создания процедуры до момента ее выполнения может устареть, а индексы могут стать неэффективными. И хотя можно обновить статистику и добавить новые, более эффективные индексы, план выполнения процедуры уже составлен, то есть процедура скомпилирована, и в результате способ доступа к данным может перестать быть эффективным. Поэтому имеется возможность проводить перекомпиляцию процедур при каждом вызове.
С другой стороны, на перекомпиляцию каждый раз будет уходить время. Поэтому вопрос об эффективности перекомпиляции процедуры или единовременного составления плана ее выполнения является довольно тонким и должен рассматриваться для каждого конкретного случая отдельно.
Хранимые процедуры могут быть выполнены либо на локальной машине, либо на удаленной системе SQL Server. Это дает возможность активизировать процессы на других машинах и работать не только с локальными базами данных, но и с информацией на нескольких серверах.
Прикладные программы, написанные на одном из языков высокого уровня, таком как С или Visual Basic .NET, также могут вызывать хранимые процедуры, что обеспечивает оптимальное решение по распределению нагрузки между программным обеспечением клиентской части и SQL-сервера.
Для создания хранимой процедуры применяется инструкция Create Procedure . Имя хранимой процедуры может быть длиной до 128 символов, включая символы # и ## . Синтаксис определения процедуры:
CREATE PROC имя_процедуры [; число]
[{@параметр тип_данных} [= значение_по_умолчанию] ] [,...n]
AS
<Инструкции_SQL>
Рассмотрим параметры этой команды:
Рассмотрим пример хранимой процедуры. Разработаем хранимую процедуру, которая подсчитывает и выводит на экран количество экземпляров книг, которые в настоящий момент находятся в библиотеке:
CREATE Procedure Count_Ex1
-- процедура подсчета количества экземпляров книг,
-- находящихся в настоящий момент в библиотеке,
-- а не на руках у читателей
As
-- зададим временную локальную переменную
Declare @N int
Select @N = count(*) from Exemplar Where Yes_No = "1"
Select @N
GO
Поскольку хранимая процедура является полноценным компонентом базы данных, то, как вы уже поняли, создать новую процедуру можно только для текущей базы данных. При работе в SQL Server Query Analyzer установление текущей базы данных выполняется с помощью оператора Use , за которым следует имя базы данных, где должна быть создана хранимая процедура. Выбрать текущую базу данных можно также с помощью раскрывающегося списка.
После создания в системе хранимой процедуры SQL Server компилирует ее и проверяет выполняемые подпрограммы. При возникновении каких-либо проблем процедура отвергается. Перед повторной трансляцией ошибки должны быть устранены.
В SQL Server 2000 используется отложенное распознавание имен (delayed name resolution), поэтому если хранимая процедура содержит обращение к другой, еще не реализованной процедуре, то выводится предупреждение, но вызов несуществующей процедуры сохраняется.
Если вы оставляете в системе обращение к неустановленной хранимой процедуре, при попытке ее выполнения пользователь получит сообщение об ошибке.
Создать хранимую процедуру можно также с помощью SQL Server Enterprise Manager:
Для того чтобы проверить работоспособность созданной хранимой процедуры, необходимо перейти в Query Analyzer и запустить процедуру на исполнение оператором EXEC <имя процедуры> . Результаты запуска созданной нами процедуры представлены на рис. 4.

Рис. 4. Запуск хранимой процедуры в Query Analyzer

Рис. 5. Результат выполнения процедуры без оператора вывода на экран
Хранимые процедуры это очень мощный инструмент, но максимальной эффективности можно добиться, только сделав их динамическими. Разработчик должен иметь возможность передавать хранимой процедуре значения, с которыми она будет работать, то есть параметры. Ниже приведены основные принципы применения параметров в хранимых процедурах.
Ниже показано определение процедуры, имеющей один входной параметр. Изменим предыдущее задание и будем считать не все экземпляры книг, а только экземпляры определенной книги. Книги у нас однозначно идентифицируются по уникальному ISBN, так что этот параметр мы и будем передавать в процедуру. В этом случае текст хранимой процедуры изменится и будет иметь следующий вид:
Create Procedure Count_Ex(@ISBN varchar(14))
As
Declare @N int
Select @N
GO
При запуске этой процедуры на исполнение мы должны передать ей значение входного параметра (рис. 6).

Рис. 6. Запуск процедуры с передачей параметра
Для создания нескольких версий одной и той же процедуры, имеющих одинаковое имя, следует после основного имени поставить точку с запятой и целое число. Как это сделать, показано в следующем примере, где описано создание двух процедур с одним и тем же именем, но с разными номерами версий (1 и 2). Номер служит для контроля выполняемой версии этой процедуры. Если номер версии не указан, выполняется первая версия процедуры. Эта опция не показана в предыдущем примере, но, тем не менее, она доступна для вашего приложения.
Для вывода сообщения, идентифицирующего версию, обе процедуры применяют инструкцию print . Первая версия считает количество свободных экземпляров, а вторая количество экземпляров на руках для данной книги.
Текст обеих версий процедур приведен ниже:
CREATE Procedure Count_Ex_all; 1
(@ISBN varchar(14))
-- процедура подсчета свободных экземпляров заданной книги
As
Declare @N int
Select @N = count(*) from Exemplar Where ISBN = @ISBN and Yes_No = "1"
Select @N
--
GO
--
CREATE Procedure Count_Ex_all; 2
(@ISBN varchar(14))
-- процедура подсчета свободных экземпляров заданной книги
As
Declare @N1 int
Select @N1 = count(*) from Exemplar Where ISBN = @ISBN and Yes_No = "0"
Select @N1
GO
Результаты выполнения процедуры с разными версиями приведены на рис. 7.

Рис. 7. Результаты запуска разных версий одной и той же хранимой процедуры
При написании нескольких версий необходимо помнить следующие ограничения: так как все версии процедуры компилируются вместе, то все локальные переменные считаются общими. Поэтому, если это требуется по алгоритму обработки, необходимо использовать разные имена внутренних переменных, что мы и сделали, назвав во второй процедуре переменную @N именем @N1 .
Написанные нами процедуры не возвращают ни одного параметра, они просто выводят на экран полученное число. Однако чаще всего нам требуется получить параметр для дальнейшей обработки. Существует несколько способов возврата параметров из хранимой процедуры. Самый простой это воспользоваться оператором возврата значений RETURN . Этот оператор позволят вернуть одно числовое значение. Но мы должны указать имя переменной или выражение, которое присваивается возвращаемому параметру. Ниже перечислены значения, возвращаемые оператором RETURN , зарезервированные системой:
| Код | Значение |
| 0 | Все нормально |
| 1 | Объект не найден |
| 2 | Ошибка типа данных |
| 3 | Процесс стал жертвой «дедлока» |
| 4 | Ошибка доступа |
| 5 | Синтаксическая ошибка |
| 6 | Некоторая ошибка |
| 7 | Ошибка с ресурсами (нет места) |
| 8 | Произошла исправимая внутренняя ошибка |
| 9 | Системный лимит исчерпан |
| 10 | Неисправимое нарушение внутренней целостности |
| 11 | То же самое |
| 12 | Разрушение таблицы или индекса |
| 13 | Разрушение базы данных |
| 14 | Ошибка оборудования |
Таким образом, чтобы не противоречить системе, мы можем возвращать через этот параметр только целые положительные числа.
Например, мы можем изменить текст ранее написанной хранимой процедуры Count_ex следующим образом:
Create Procedure Count_Ex2(@ISBN varchar(14))
As
Declare @N int
Select @N = count(*) from Exemplar
Where ISBN = @ISBN and YES_NO = "1"
-- возвращаем значение переменной @N,
-- если значение переменной не определено, возвращаем 0
Return Coalesce(@N, 0)
GO
Теперь мы можем получить значение переменной @N и использовать его для дальнейшей обработки. В этом случае возвращаемое значение присваивается самой хранимой процедуре, и для того чтобы его проанализировать, можно использовать следующий формат оператора вызова хранимой процедуры:
Exec <переменная> = <имя_процедуры> <значение_входных_параметров>
Пример вызова нашей процедуры приведен на рис. 8.

Рис. 8. Передача возвращаемого значения хранимой процедуры локальной переменной
Входные параметры хранимых процедур могут использовать значение по умолчанию. Это значение будет использоваться в том случае, если при вызове процедуры значение параметра было не указано.
Значение по умолчанию задается через знак равенства после описания входного параметра и его типа. Рассмотрим хранимую процедуру, которая считает количество экземпляров книг заданного года выпуска. Год выпуска по умолчанию 2006.
CREATE PROCEDURE ex_books_now(@year int = 2006)
-- подсчет количества экземпляров книг заданного года выпуска
AS
Declare @N_books int
select @N_books = count(*) from books, exemplar
where Books.ISBN = exemplar.ISBN and YEARIZD = @year
return coalesce(@N_books, 0)
GO
На рис. 9 приведен пример вызова данной процедуры с указанием входного параметра и без него.

Рис. 9. Вызов хранимой процедуры с параметром и без параметра
Все рассмотренные выше примеры использования параметров в хранимых процедурах предусматривали только входные параметры. Однако параметры могут быть и выходные. Это означает, что значение параметра после завершения работы процедуры будет передано тому, кто вызывал эту процедуру (другой процедуре, триггеру, пакету команд и т. п.). Естественно, для того чтобы получить выходной параметр, при вызове следует указать в качестве фактического параметра не константу, а переменную.
Отметим, что определение в процедуре параметра как выходного не обязывает вас использовать его как таковой. То есть если указать в качестве фактического параметра константу, то ошибки не произойдет и она будет использована как обычный входной параметр.
Для указания того, что параметр является выходным, используется инструкция OUTPUT . Данное ключевое слово записывается после описания параметра. При описании параметров хранимых процедур желательно задавать значения выходных параметров после входных.
Рассмотрим пример использования выходных параметров. Напишем хранимую процедуру, которая для заданной книги подсчитывает общее количество ее экземпляров в библиотеке и количество свободных экземпляров. Мы не сможем здесь использовать оператор возврата RETURN , поскольку он возвращает только одно значение, поэтому нам необходимо здесь определить выходные параметры. Текст хранимой процедуры может выглядеть следующим образом:
CREATE Procedure Count_books_all
(@ISBN varchar(14), @all int output, @free int output)
-- процедура подсчета общего количества земпляров заданной книги
-- и количества свободных экземпляров
As
-- подсчет общего количесва экземпляров
Select @all = count(*) from Exemplar Where ISBN = @ISBN
Select @free = count(*) from Exemplar Where ISBN = @ISBN and Yes_No = "1"
GO
Пример выполнения данной процедуры приведен на рис. 10.

Рис. 10. Тестирование хранимой процедуры с выходными параметрами
Как уже было сказано ранее, для того чтобы получить для анализа значения выходных параметров, мы должны задать их переменными, а эти переменные должны быть описаны оператором Declare . Последний оператор вывода позволил нам просто вывести на экран полученные значения.
Параметрами процедуры могут быть даже переменные типа Cursor . Для этого переменная должна быть описана как специальный тип данных VARYING , без привязки к стандартным системным типам данных. Кроме того, обязательно должно быть указано, что это переменная типа Cursor .
Напишем простейшую процедуру, которая выводит список книг в нашей библиотеке. При этом если книг не более трех, то выводим их названия в рамках самой процедуры, а если список книг превышает заданное число, то передаем их в виде курсора вызывающей программе или модулю.
Текст процедуры выглядит следующим образом:
CREATE PROCEDURE GET3TITLES
(@MYCURSOR CURSOR VARYING OUTPUT)
-- процедура печати названий книг с курсором
AS
-- определяем локальную переменную типа Cursor в процедуре
SET @MYCURSOR = CURSOR
FOR SELECT DISTINCT TITLE
FROM BOOKS
-- открываем курсор
OPEN @MYCURSOR
-- описываем внутренние локальные переменные
DECLARE @TITLE VARCHAR(80), @CNT INT
--- устанавливаем начальное состояние счетчика книг
SET @CNT = 0
-- переходим на первую строку курсора
-- пока есть строки курсора,
-- то есть пока переход на новую строку корректен
WHILE (@@FETCH_STATUS = 0) AND (@CNT <= 2) BEGIN
PRINT @TITLE
FETCH NEXT FROM @MYCURSOR INTO @TITLE
-- изменяем состояние счетчика книг
SET @CNT = @CNT + 1
END
IF @CNT = 0 PRINT "НЕТ ПОДХОДЯЩИХ КНИГ"
GO
Пример вызова данной хранимой процедуры приведен на рис. 11.

В вызывающей процедуре курсор должен быть описан как локальная переменная. Потом мы вызвали нашу процедуру и передали ей имя локальной переменной типа Cursor . Процедура начала работать и вывела нам на экран первые три названия, а потом передала управление вызывающей процедуре, и та продолжила обработку курсора. Для этого она организовала цикл типа While по глобальной переменной @@FETCH_STATUS , которая отслеживает состояние курсора, и далее в цикле вывела все остальные строки курсора.
В окне вывода мы видим увеличенный интервал между первыми тремя строками и последующими названиями. Этот интервал как раз и показывает, что управление передано внешней программе.
Заметьте, что переменная @TITLE , являясь локальной для процедуры, будет уничтожена после завершения ее работы, поэтому в вызывающем процедуру блоке она объявляется еще раз. Создание и открытие курсора в данном примере происходит в процедуре, а закрытие, уничтожение и дополнительная обработка выполняются в блоке команд, в котором вызывается процедура.
Проще всего посмотреть текст процедуры, изменить или удалить ее с помощью графического интерфейса Enterprise Manager. Но можно это сделать и при помощи специальных системных хранимых процедур Transact-SQL. В Transact-SQL просмотр определения процедуры выполняется с помощью системной процедуры sp_helptext , а системная процедура sp_help позволяет вывести контрольную информацию о процедуре. Системные процедуры sp_helptext и sp_help используются и для просмотра таких объектов баз данных, как таблицы, правила и установки по умолчанию.
Информация обо всех версиях одной процедуры, независимо от номера, выводится сразу. Удаление разных версий одной хранимой процедуры также происходит одновременно. В следующем примере показано, как выводятся определения версий 1 и 2 процедуры Count_Ex_all , когда ее имя указано в качестве параметра системной процедуры sp_helptext (рис. 12).

Рис. 12. Просмотр текста хранимой процедуры с использованием системной хранимой процедуры
Системная процедура SP_HELP выводит характеристики и параметры созданной процедуры в следующем виде:
|
Created_datetime | |||||
|
2006-12-06 23:15:01.217 | |||||
|
Scale | Param_order Collation | ||||
|
NULL | 1 | Cyrillic_General_CI_AS | |||
|
0 | 2 | NULL | |||
|
0 | 3 | NULL | |||
Попробуйте самостоятельно расшифровать эти параметры. О чем они говорят?
Преимущество применения хранимых процедур для выполнения набора инструкций Transact-SQL состоит в том, что они компилируются при первом выполнении. В процессе компиляции инструкции Transact-SQL конвертируются из их первоначального символьного представления в исполняемую форму. Любые объекты, к которым происходит обращение в процедуре, также конвертируются в альтернативное представление. Например, имена таблиц конвертируются в идентификаторы объектов, а имена столбцов в идентификаторы столбцов.
План выполнения создается точно так же, как и для выполнения одной инструкции Transact-SQL. Этот план содержит, например, индексы, применяемые для считывания строк из таблиц, к которым обращается процедура. План выполнения процедуры сохраняется в кэше и используется при каждом ее вызове.
Замечание: Размер кэша процедуры можно определить так, чтобы он мог содержать большинство или все доступные для выполнения процедуры. Это сохранит время, необходимое для повторной генерации плана процедур.
Обычно план выполнения находится в кэше процедур. Это позволяет увеличить производительность при его выполнении. Однако при некоторых обстоятельствах процедура автоматически перекомпилируется.
SQL Server стремится оптимизировать хранимые процедуры путем кэширования наиболее интенсивно используемых процедур. Поэтому старый план выполнения, загруженный в кэш, может быть использован вместо нового плана. Для предотвращения этой проблемы следует удалить и заново создать хранимую процедуру или остановить и заново активизировать SQL Server. Это очистит кэш процедуры и исключит вероятность работы со старым планом выполнения.
Процедуру можно также создать с опцией WITH RECOMPILE . В этом случае она будет автоматически перекомпилироваться при каждом выполнении. Опцию WITH RECOMPILE следует применять в случаях, когда процедура обращается к очень динамичным таблицам, строки которых часто добавляются, удаляются или обновляются, поскольку это приводит к значительным изменениям в определенных для таблиц индексах.
Если повторная компиляция процедур не производится автоматически, ее можно выполнить принудительно. Например, если обновлены статистики, применяющиеся для определения возможности использования индекса в данном запросе, или если создан новый индекс, должна быть произведена принудительная перекомпиляция. Для выполнения принудительной повторной компиляции в инструкции EXECUTE применяется предложение WITH RECOMPILE :
EXECUTE имя_процедуры;
AS
<инструкции Transact-SQL>
WITH RECOMPILE
Если процедура работает с параметрами, контролирующими порядок ее выполнения, следует использовать опцию WITH RECOMPILE . Если параметры хранимой процедуры могут определить лучший путь ее выполнения, рекомендуется формировать план выполнения в процессе работы, а не создавать его при первом вызове процедуры для использования при всех последующих обращениях.
Замечание: Иногда бывает сложно определить, надо ли использовать опцию WITH RECOMPILE при создании процедуры или нет. Если есть сомнения, лучше не применять эту опцию, так как повторная компиляция процедуры при каждом выполнении приведет к потере очень ценного времени центрального процессора. Если в будущем вам понадобится повторная компиляция при выполнении хранимой процедуры, ее можно будет произвести, добавив предложение WITH RECOMPILE к инструкции EXECUTE .
Нельзя применять опцию WITH RECOMPILE в инструкции CREATE PROCEDURE , содержащей опцию FOR REPLICATION . Эту опцию применяют для создания процедуры, которая выполняется в процессе репликации.
В хранимых процедурах может производиться вызов других хранимых процедур, однако при этом имеется ограничение по уровню вложенности. Максимальный уровень вложенности 32. Текущий уровень вложенности можно определить с помощью глобальной переменной @@NESTLEVEL .
В MS SQL SERVER 2000 существует множество заранее определенных функций, позволяющих выполнять разнообразные действия. Однако всегда может возникнуть необходимость использовать какие-то специфичные функции. Для этого, начиная с версии 8.0 (2000), появилась возможность описывать пользовательские функции (User Defined Functions, UDF) и хранить их в виде полноценного объекта базы данных, наравне с хранимыми процедурами, представлениями и т. д.
Удобство применения функций, определяемых пользователем, очевидно. В отличие от хранимых процедур, функции можно встраивать непосредственно в оператор SELECT , причем использовать их как для получения конкретных значений (в разделе SELECT ), так и в качестве источника данных (в разделе FROM ).
При использовании UDF в качестве источников данных их преимущество перед представлениями заключается в том, что UDF, в отличие от представлений, могут иметь входные параметры, с помощью которых можно влиять на результат работы функции.
Функции, определяемые пользователем, могут быть трех видов: скалярные функции , inline-функции и многооператорные функции, возвращающие табличный результат . Рассмотрим все эти типы функций подробнее.
Скалярные функции возвращают один скалярный результат. Этот результат может быть любого описанного выше типа, за исключением типов text , ntext , image и timestamp . Это наиболее простой вид функции. Ее синтаксис имеет следующий вид:
RETURNS скалярный_тип_данных
BEGIN
тело_функции
RETURN скалярное_выражение
END
Рассмотрим примеры использования скалярных функций.
Создать функцию, которая из двух целых чисел, подаваемых на вход в виде параметров, будет выбирать наименьшее.
Пусть функция выглядит следующим образом:
CREATE FUNCTION min_num(@a INT, @b INT)
RETURNS INT
BEGIN
DECLARE @c INT
IF @a < @b SET @c = @a
ELSE SET @c = @b
RETURN @c
END
Выполним теперь эту функцию:
SELECT dbo.min_num(4, 7)
В результате мы получим значение 4.
Можно применить эту функцию для нахождения наименьшего среди значений столбцов таблицы:
SELECT min_lvl, max_lvl, min_num(min_lvl, max_lvl)
FROM Jobs
Создадим функцию, которая будет получать на вход параметр типа datetime и возвращать дату и время, соответствующие началу указанного дня. Например, если входной параметр 20.09.03 13:31, то результатом будет 20.09.03 00:00.
CREATE FUNCTION dbo.daybegin(@dat DATETIME)
RETURNS smalldatetime AS
BEGIN
RETURN CONVERT(datetime, FLOOR(convert(FLOAT, @dat)))
END
Здесь функция CONVERT осуществляет преобразование типов. Сначала тип даты-времени приводится к типу FLOAT . При таком приведении целая часть это число дней, считая с 1 января 1900 года, а дробная время. Далее происходит округление до меньшего целого с помощью функции FLOOR и приведение к типу даты-времени.
Проверим действие функции:
SELECT dbo.daybegin(GETDATE())
Здесь GETDATE() функция, возвращающая текущую дату и время.
Предыдущие функции использовали при вычислении только входные параметры. Однако можно использовать и данные, хранящиеся в базе данных.
Создадим функцию, которая будет принимать в качестве параметров две даты: начало и окончание временного интервала и рассчитывать суммарную выручку от продаж за этот интервал. Дата продажи и количество будут браться из таблицы Sales , а цены на продаваемые издания в таблице Titles .
CREATE FUNCTION dbo.SumSales(@datebegin DATETIME, @dateend DATETIME)
RETURNS Money
AS
BEGIN
DECLARE @Sum Money
SELECT @Sum = sum(t.price * s.qty)
RETURN @Sum
END
Этот вид функций возвращает в качестве результата не скалярное значение, а таблицу, вернее набор данных. Это может быть очень удобно в тех случаях, когда в разных процедурах, триггерах и т. д. часто выполняется однотипный подзапрос. Тогда, вместо того чтобы везде писать этот запрос, можно создать функцию и в дальнейшем использовать ее.
Еще более полезны функции такого типа в тех случаях, когда требуется, чтобы возвращаемая таблица зависела от входных параметров. Как известно, представления не могут иметь параметров, поэтому проблему такого рода могут решить только inline-функции.
Особенностью inline-фукций является то, что они могут содержать только один запрос в своем теле. Таким образом, функции этого типа очень напоминают представления, но дополнительно могут иметь входные параметры. Синтаксис inline-функции:
CREATE FUNCTION [владелец.]имя_функции
([{@имя_параметра скалярный_тип_данных [= значение_по_умолчанию]} [,
n]])
RETURNS TABLE
RETURN [(<запрос>)]
В определении функции указано, что она будет возвращать таблицу; <запрос> это тот запрос, результат выполнения которого будет результатом работы функции.
Напишем функцию, аналогичную скалярной функции из последнего примера, но возвращающую не только суммирующий результат, но и строки продаж, включающие дату продажи, название книги, цену, количество штук и сумму продажи. Должны выбираться только те продажи, которые попадают в заданный период времени. Зашифруем текст функции, чтобы другие пользователи могли ей воспользоваться, но не могли читать и исправлять ее:
CREATE FUNCTION Sales_Period (@datebegin DATETIME, @dateend DATETIME)
RETURNS TABLE
WITH ENCRYPTION
AS
RETURN (
SELECT t.title, t.price, s.qty, ord_date, t.price * s.qty as stoim
FROM Titles t JOIN Sales s ON t.title_Id = s.Title_ID
WHERE ord_date BETWEEN @datebegin and @dateend
)
Теперь вызовем эту функцию. Как уже говорилось, вызвать ее можно только в разделе FROM оператора SELECT :
SELECT * FROM Sales_Period("01.09.94", "13.09.94")
Первый рассмотренный тип функций позволял использовать сколь угодно много инструкций на Transact-SQL, но возвращал только скалярный результат. Второй тип функций мог возвращать таблицы, но его тело представляет только один запрос. Многооператорные функции, возвращающие табличный результат, позволяют сочетать свойства первых двух функций, то есть могут содержать в теле много инструкций на Transact-SQL и возвращать в качестве результата таблицу. Синтаксис многооператорной функции:
CREATE FUNCTION [владелец.]имя_функции
([{@имя_параметра скалярный_тип_данных [= значение_по_умолчанию]} [,... n]])
RETURNS @имя_переменной_результата TABLE
<описание_таблицы>
BEGIN
<тело_функции>
RETURN
END
Теперь рассмотрим пример, который можно выполнить только с помощью функций этого типа.
Пусть имеется дерево каталогов и лежащих в них файлов. Пусть вся эта структура описана в базе данных в виде таблиц (рис. 13). По сути, здесь мы имеем иерархическую структуру для каталогов, поэтому на схеме указана связь таблицы Folders с самой собой.

Рис. 13. Структура базы данных для описания иерархии файлов и каталогов
Теперь напишем функцию, которая будет принимать на входе идентификатор каталога и выводить все файлы, которые хранятся в нем и во всех каталогах вниз по иерархии. Например, если в каталоге Институт созданы каталоги Факультет1 , Факультет2 и т. д., в них есть каталоги кафедр, и в каждом из каталогов есть файлы, то при указании в качестве параметра нашей функции идентификатора каталога Институт должен быть выведен список всех файлов для всех этих каталогов. Для каждого файла должно выводиться имя, размер и дата создания.
Решить задачу с помощью inline-функции нельзя, поскольку SQL не предназначен для выполнения иерархических запросов, так что одним SQL-запросом здесь не обойтись. Скалярная функция тоже не может быть применена, поскольку результат должен быть таблицей. Тут нам на помощь и придет многооператорная функция, возвращающая таблицу:
CREATE FUNCTION dbo.GetFiles(@Folder_ID int)
RETURNS @files TABLE(Name VARCHAR(100), Date_Create DATETIME, FileSize INT) AS
BEGIN
DECLARE @tmp TABLE(Folder_Id int)
DECLARE @Cnt INT
INSERT INTO @tmp values(@Folder_ID)
SET @Cnt = 1
WHILE @Cnt <> 0 BEGIN
INSERT INTO @tmp SELECT Folder_Id
FROM Folders f JOIN @tmp t ON f.parent=t.Folder_ID
WHERE F.id NOT IN(SELECT Folder_ID FROM @tmp)
SET @Cnt = @@ROWCOUNT
END
INSERT INTO @Files(Name, Date_Create, FileSize)
SELECT F.Name, F.Date_Create, F.FileSize
FROM Files f JOIN Folders Fl on f.Folder_id = Fl.id
JOIN @tmp t on Fl.id = t.Folder_Id
RETURN
END
Здесь в цикле в переменную @tmp добавляются все вложенные каталоги на всех уровнях вложенности до тех пор, пока больше не останется вложенных каталогов. Затем в переменную результата @Files записываются все необходимые атрибуты файлов, находящихся в каталогах, перечисленных в переменной @tmp .
Необходимо создать и отладить пять хранимых процедур из следующего обязательного списка:
Процедура 1. Увеличение на неделю срока сдачи экземпляров книги, если текущий срок сдачи лежит в пределах от трех дней до текущей даты до трех дней после текущей даты.
Процедура 2. Подсчет количества свободных экземпляров заданной книги.
Процедура 3. Проверка существования читателя с заданными фамилией и датой рождения.
Процедура 4. Ввод нового читателя с проверкой его существования в базе и определением его нового номера читательского билета.
Процедура 5. Подсчет штрафа в денежном выражении для читателей-должников.
Для каждой записи в таблице Exemplar проверяется, попадает ли дата сдачи книги в заданный временной интервал. Если попадает, то дата возврата книги увеличивается на неделю. При выполнении процедуры необходимо использовать функцию по работе с датами:
DateAdd(day, <число добавляемых дней>, <начальная дата>)
Входным параметром процедуры является ISBN уникальный шифр книги. Процедура возвращает 0 (ноль), если все экземпляры данной книги находятся на руках у читателей. Процедура возвращает значение N , равное числу экземпляров книги, которые в данный момент находятся на руках у читателей.
Если книги с заданным ISBN нет в библиотеке, то процедура возвращает 100 (минус сто).
Процедура возвращает номер читательского билета, если читатель с такими данными существует, и 0 (ноль) в противном случае.
При сравнении даты рождения необходимо использовать функцию преобразования Convert() для преобразования даты рождения символьной переменной типа Varchar(8) , используемой в качестве входного параметра процедуры, в данные типа datatime , которые используются в таблице Readers . В противном случае операция сравнения при поиске данного читателя не сработает.
Процедура имеет пять входных и три выходных параметра.
Входные параметры:
Выходные параметры:
Процедура работает с курсором, который содержит перечень номеров читательских билетов всех должников. В процессе работы должна быть создана глобальная временная таблица ##DOLG , в которую для каждого должника будет занесен его суммарный долг в денежном выражении за все книги, которые он продержал дольше срок возврата. Денежная компенсация исчисляется в 0,5 % от цены за книгу за день задержки.

Приведенные ниже дополнительные хранимые процедуры предназначены для индивидуальных заданий.
Процедура 6. Подсчет количества книг по заданной предметной области, которые имеются в настоящий момент в библиотеке хотя бы в одном экземпляре. Предметная область передается как входной параметр.
Процедура 7. Ввод новой книги с указанием количества ее экземпляров. При вводе экземпляров новой книги не забудьте ввести их корректные инвентарные номера. Подумайте, как это можно сделать. Напоминаю, что у вас есть функции Max и Min , которые позволяют найти максимальное или минимальное значение любого числового атрибута средствами запроса Select .
Процедура 8. Формирование таблицы со списком читателей-должников, то есть тех, кто должен был вернуть книги в библиотеку, но еще не вернул. В результирующей таблице каждый читатель-должник должен появляться только один раз, вне зависимости от того, сколько книг он задолжал. Кроме ФИО и номера читательского билета в результирующей таблице надо указать адрес и телефон.
Процедура 9. Поиск свободного экземпляра по заданному названию книги. Если свободный экземпляр есть, то процедура возвращает инвентарный номер экземпляра; если нет, то процедура возвращает список читателей, у которых эта книга находится, с указанием даты возврата книги и телефона читателя.
Процедура 10. Вывод списка читателей, которые не держат ни одной книги на руках в настоящий момент. В списке указать ФИО и телефон.
Процедура 11. Вывод списка книг с указанием количества экземпляров данной книги в библиотеке и количества свободных экземпляров на текущий момент.
CREATE PROCEDURE имя_процедуры (параметры) begin операторы end
Параметры это те данные, которые мы будем передавать процедуре при ее вызове, а операторы - это собственно запросы. Давайте напишем свою первую процедуру и убедимся в ее удобстве. В уроке 10 , когда мы добавляли новые записи в БД shop, мы использовали стандартный запрос на добавление вида:
INSERT INTO customers (name, email) VALUE ("Иванов Сергей", "[email protected]");
Т.к. подобный запрос мы будем использовать каждый раз, когда нам необходимо будет добавить нового покупателя, то вполне уместно оформить его в виде процедуры:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50)) begin insert into customers (name, email) value (n, e); end
Обратите внимание, как задаются параметры: необходимо дать имя параметру и указать его тип, а в теле процедуры мы уже используем имена
параметров.
Один нюанс. Как вы помните, точка с запятой означает конец запроса и отправляет его на выполнение, что в данном случае неприемлемо. Поэтому, прежде,
чем написать процедуру необходимо переопределить разделитель с; на "//", чтобы запрос не отправлялся раньше времени. Делается это с помощью
оператора DELIMITER //
:

Таким образом, мы указали СУБД, что выполнять команды теперь следует после //. Следует помнить, что переопределение разделителя осуществляется только на один сеанс работы, т.е. при следующем сеансе работы с MySql разделитель снова станет точкой с запятой и при необходимости его придется снова переопределять. Теперь можно разместить процедуру:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50)) begin insert into customers (name, email) value (n, e); end //

Итак, процедура создана. Теперь, когда нам понадобится ввести нового покупателя нам достаточно ее вызвать, указав необходимые параметры. Для вызова хранимой процедуры используется оператор CALL , после которого указывается имя процедуры и ее параметры. Давайте добавим нового покупателя в нашу таблицу Покупатели (customers):
call ins_cust("Сычов Валерий", "[email protected]")//

Согласитесь, что так гораздо проще, чем писать каждый раз полный запрос. Проверим, работает ли процедура, посмотрев, появился ли новый покупатель в таблице Покупатели (customers):

Появился, процедура работает, и будет работать всегда, пока мы ее не удалим с помощью оператора DROP PROCEDURE название_процедуры .
Как было сказано в начале урока, процедуры позволяют объединить последовательность запросов. Давайте посмотрим, как это делается. Помните в уроке 11 мы хотели узнать, на какую сумму нам привез товар поставщик "Дом печати"? Для этого нам пришлось использовать вложенные запросы, объединения, вычисляемые столбцы и представления. А если мы захотим узнать, на какую сумму нам привез товар другой поставщик? Придется составлять новые запросы, объединения и т.д. Проще один раз написать хранимую процедуру для этого действия.
Казалось бы, проще всего взять уже написанные в уроке 11 представление и запрос к нему, объединить в хранимую процедуру и сделать идентификатор поставщика (id_vendor) входным параметром, вот так:
CREATE PROCEDURE sum_vendor(i INT) begin CREATE VIEW report_vendor AS SELECT magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity*prices.price AS summa FROM magazine_incoming, prices WHERE magazine_incoming.id_product= prices.id_product AND id_incoming= (SELECT id_incoming FROM incoming WHERE id_vendor=i); SELECT SUM(summa) FROM report_vendor; end //
Но так процедура работать не будет. Все дело в том, что в представлениях не могут использоваться параметры . Поэтому нам придется несколько изменить последовательность запросов. Сначала мы создадим представление, которое будет выводить идентификатор поставщика (id_vendor), идентификатор продукта (id_product), количество (quantity), цену (price) и сумму (summa) из трех таблиц Поставки (incoming), Журнал поставок (magazine_incoming), Цены (prices):
CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity*prices.price AS summa FROM incoming, magazine_incoming, prices WHERE magazine_incoming.id_product= prices.id_product AND magazine_incoming.id_incoming= incoming.id_incoming;
А потом создадим запрос, который просуммирует суммы поставок интересующего нас поставщика, например, с id_vendor=2:
Вот теперь мы можем объединить два этих запроса в хранимую процедуру, где входным параметром будет идентификатор поставщика (id_vendor), который будет подставляться во второй запрос, но не в представление:
CREATE PROCEDURE sum_vendor(i INT) begin CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity*prices.price AS summa FROM incoming, magazine_incoming, prices WHERE magazine_incoming.id_product= prices.id_product AND magazine_incoming.id_incoming= incoming.id_incoming; SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i; end //

Проверим работу процедуры, с разными входными параметрами:

Как видите, процедура срабатывает один раз, а затем выдает ошибку, говоря нам, что представление report_vendor уже имеется в БД. Так происходит потому, что при обращении к процедуре в первый раз, она создает представление. При обращении во второй раз, она снова пытается создать представление, но оно уже есть, поэтому и появляется ошибка. Чтобы избежать этого возможно два варианта.
Первый - вынести представление из процедуры. То есть мы один раз создадим представление, а процедура будет лишь к нему обращаться, но не создавать его. Предварительно не забудет удалить уже созданную процедуру и представление:
DROP PROCEDURE sum_vendor// DROP VIEW report_vendor// CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity*prices.price AS summa FROM incoming, magazine_incoming, prices WHERE magazine_incoming.id_product= prices.id_product AND magazine_incoming.id_incoming= incoming.id_incoming// CREATE PROCEDURE sum_vendor(i INT) begin SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i; end //
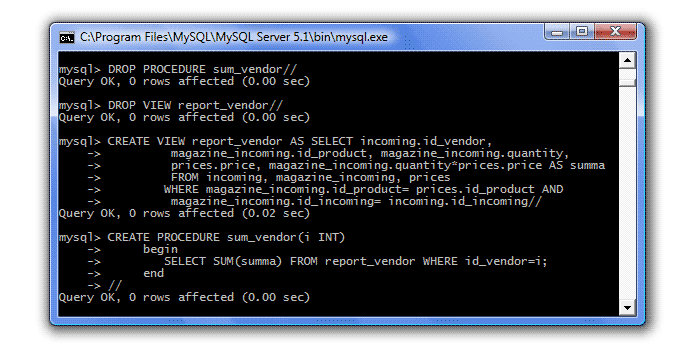
Проверяем работу:
call sum_vendor(1)// call sum_vendor(2)// call sum_vendor(3)//

Второй вариант - прямо в процедуре дописать команду, которая будет удалять представление, если оно существует:
CREATE PROCEDURE sum_vendor(i INT) begin DROP VIEW IF EXISTS report_vendor; CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity*prices.price AS summa FROM incoming, magazine_incoming, prices WHERE magazine_incoming.id_product= prices.id_product AND magazine_incoming.id_incoming= incoming.id_incoming; SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i; end //
Перед использованием этого варианта не забудьте удалить процедуру sum_vendor, а затем проверить работу:

Как видите, сложные запросы или их последовательность действительно проще один раз оформить в хранимую процедуру, а дальше просто обращаться к ней, указывая необходимые параметры. Это значительно сокращает код и делает работу с запросами более логичной.
Для программирования расширенных хранимых процедур Microsoft предоставляет ODS (Open Data Service) API набор макросов и функций, используемых для построения серверных приложений позволяющих расширить функциональность MS SQL Server 2000.
Расширенные хранимые процедуры - это обычные функции написанные на С/C++ с применением ODS API и WIN32 API, оформленные в виде библиотеки динамической компоновки (dll) и призванные, как я уже говорил, расширять функциональность SQL сервера. ODS API предоставляет разработчику богатый набор функций позволяющих передавать данные клиенту, полученные от любых внешних источников данных (data source) в виде обычных наборов записей (record set). Так же, extended stored procedure может возвращать значения через переданный ей параметр (OUTPUT parametr).
Как работают расширенные хранимые процедуры.
Особенности расширенных хранимых процедур.
Создание расширенных хранимых процедур.
Расширенная хранимая процедура эта функция имеющая следующий прототип:
SRVRETCODE xp_extendedProcName (SRVPROC * pSrvProc);
Параметр pSrvProc
указатель на SRVPROC структуру, которая является описателем (handle) каждого конкретного клиентского подключения. Поля этой структуры недокументированны и содеражат информацию, которую библиотека ODS использует для управления коммуникацией и данными между серверным приложением (Open Data Services server application) и клиентом. В любом случае, Вам не потребуется обращаться к этой структуре и тем более нельзя модифицоравать её. Этот параметр требуется указывать при вызове любой функции ODS API, поэтому в дальнейшем я небуду останавливаться на его описании.
Использование префикса xp_ необязательно, однако существует соглашение начинать имя расширенной хранимой процедуры именно так, чтобы подчеркнуть отличие от обычной хранимой процедуры, имена которых, как Вы знаете, принято начинать с префикса sp_.
Так же следует помнить, что имена расширенных хранимых процедур чувствительны к регистру. Не забывайте об этом, когда будете вызвать расширенную хранимую процедуру, иначе вместо ожидаемого результата, Вы получите сообщение об ошибке.
Если Вам необходимо написать код инициализации/деинициализации dll, используйте для этого стандартную функцию DllMain(). Если у Вас нет такой необходимости, и вы не хотите писать DLLMain(), то компилятор соберёт свою версию функции DLLMain(), которая ничего не делает, а просто возвращает TRUE. Все функции, вызываемые из dll (т.е. расширенные хранимые процедуры) должны быть объявлены, как экспортируемые. Если Вы пишете на MS Visual C++ используйте директиву __declspec(dllexport)
. Если Ваш компилятор не поддерживает эту директиву, опишите экспортируемую функцию в секции EXPORTS в DEF файле.
Итак, для создания проекта, нам понадобятся следующие файлы:
Declspec(dllexport) ULONG __GetXpVersion()
{
return ODS_VERSION;
}
Когда MS SQL Server загружает DLL c extended stored procedure, он первым делом вызывает эту функцию, чтобы получить информацию о версии используемой библиотеки.
Для написания своей первой extended stored procedure, Вам понадобится установить на свой компьютер:
MS SQL Server 2000 любой редакции (у меня стоит Personal Edition). В процесе инсталляции обязательно выберите опцию source sample
- MS Visual C++ (я использовал версию 7.0), но точно знаю подойдёт и 6.0
Установка SQL Server -a нужна для тестирования и отладки Вашей DLL. Возможна и отладка по сети, но я этого никогда не делал, и поэтому установил всё на свой локальный диск. В поставку Microsoft Visual C++ 7.0 редакции Interprise Edition входит мастер Extended Stored Procedure DLL Wizard. В принципе, ничего сверх естественного он не делает, а только генерирует заготовку шаблон расширенной хранимой процедуры. Если Вам нравятся мастера, можете использовать его. Я же предпочитаю делать всё ручками, и поэтому не буду рассматривать этот случай.
Теперь к делу:
- Запустите Visual C++ и создайте новый проект - Win32 Dynamic Link Library.
- Включите в проект заголовочный файл - #include
- Зайдите в меню Tools => Options и добавьте пути поиска include и library файлов. Если, при установке MS SQL Server, Вы ничего не меняли, то задайте:
C:Program FilesMicrosoft SQL Server80ToolsDevToolsInclude для заголовочных файлов;
- C:Program FilesMicrosoft SQL Server80ToolsDevToolsLib для библиотечных файлов.
- Укажите имя библиотечного файла opends60.lib в опциях линкера.
На этом подготовительный этап закончен, можно приступать к написанию своей первой extended stored procedure.
Постановка задачи.
Прежде чем приступать к программированию, необходимо чётко представлять с чего начать, какой должен быть конечный результат, и каким способом его добиться. Итак, вот нам техническое задание:
Разработать расширенную хранимую процедуру для MS SQL Server 2000, которая получает полный список пользователей зарегистрированных в домене, и возвращает его клиенту в виде стандартного набора записей (record set). В качестве первого входного параметра функция получает имя сервера содержащего базу данных каталога (Active Directory), т.е имя контролера домена. Если этот параметр равен NULL, тогда необходимо передать клиенту список локальных групп. Второй параметр будет использоваться extended stored procedure для возварата значения результата успешной/неуспешной работы (OUTPUT параметр). Если, расширенная хранимая процедура выполнена успешно, тогда необходимо передать количество записей возвращённых в клиентский record set , если в процессе работы не удалось получить требуемую информацию, значение второго параметра необходимо установить в -1, как признак неуспешного завершения.
Условный прототип расширенной хранимой процедуры следующий:
xp_GetUserList(@NameServer varchar, @CountRec int OUTPUT);
#include
#include
#define XP_NOERROR 0
#define XP_ERROR -1
__declspec(dllexport) SERVRETCODE xp_GetGroupList(SRVPROC* pSrvProc)
{
//Проверка кол-ва переданных параметров
//Проверка типа переданных параметров
//Проверка, является ли параметр 2 OUTPUT параметром
//Проверка, имеет ли параметр 2 достаточную длину для сохранения значения
//Получение входных параметров
//Получение списка пользователей
// Посылка полученных данных клиенту в виде стандартного набора записей (record set)
//Установка значения OUTPUT параметра
return (XP_NOERROR);
}
Работа с входными параметрами
В этой главе я не хочу рассеивать Ваше внимание на посторонних вещах, а хочу сосредоточить его на работе с переданными в расширенную хранимую процедуру параметрами. Поэтуму мы несколько упростим наше техническое задание и разработаем тольку ту его часть, которая работает с входными параметрами. Но сначал не много теории
Первое действие, которое должна выполнить наша exteneded stored procedure , - получить параметры, которые были переданы ей при вызове. Следуя приведённому выше алгоритму нам необходимо выполнить следующие действия:
Определить кол-во переданных параметров;
- Убедится, что переданные параметры имеют верный тип данных;
- Убедиться, что указанный OUTPUT параметр имеет достаточную длину, для сохранения в нём значения возвращаемого нашей extended stored procedure.
- Получить переданные параметры;
- Установить значения выходного параметра как результат успешного/неуспешного завершения работы extended stored procedure .
Теперь рассмотрим подробно каждый пункт:
Определение количества переданных в расширенную хранимую процедуру параметров
Для получения количества переданных параметров необходимо использовать функцию:
int srv_rpcparams (SRV_PROC * srvproc);
Определение типа данных и длины переданых параметров
Для получения информации о типе и длине переданных параметров Microsoft рекомендует использовать функцию srv_paramifo. Эта универсальная функция заменяет вызовы srv_paramtype, srv_paramlen, srv_parammaxlen, которые теперь считаются устаревшими. Вот её прототип:
int srv_paraminfo (
SRV_PROC * srvproc,
int n,
BYTE * pbType,
ULONG* pcbMaxLen,
ULONG * pcbActualLen,
BYTE * pbData,
BOOL * pfNull);
Проверка, является ли второй параметр OUTPUT параметром.
Функция srv_paramstatus() предназначена для определения статуса переданного параметра:
int srv_paramstatus (
SRV_PROC * srvproc,
int n
);
n номер параметра переданного в расширенную хранимую процедуру при вызове. Напомню: параметры всегда нумеруются с 1.
Для возврата значения, srv_paramstatus использует нулевой бит. Если он установлен в 1 переданный параметр является OUTPUT параметром, если в 0 обычным параметром, переданным по значению. Если, exteneded stored procedure была вызвана без параметров, функция вернёт -1.
Установка значения выходного параметра.
Выходному параметру, переданному в расширеную хранимую можно передать значение используя функцию srv_paramsetoutput. Эта новая функция заменяет вызов функции srv_paramset, которая теперь считается устаревашай, т.к. не поддерживает новые типы данных введённые в ODS API и данные нулевой длины.
int srv_paramsetoutput (
SRV_PROC *srvproc,
int n,
BYTE *pbData,
ULONG cbLen,
BOOL fNull
);
#include
#define XP_NOERROR 0
#define XP_ERROR 1
#define MAX_SERVER_ERROR 20000
#define XP_HELLO_ERROR MAX_SERVER_ERROR+1
void printError (SRV_PROC*, CHAR*);
#ifdef __cplusplus
extern "C" {
#endif
SRVRETCODE __declspec(dllexport) xp_helloworld(SRV_PROC* pSrvProc);
#ifdef __cplusplus
}
#endif
SRVRETCODE xp_helloworld(SRV_PROC* pSrvProc)
{
char szText = "Hello World!";
BYTE bType;
ULONG cbMaxLen;
ULONG cbActualLen;
BOOL fNull;
/* Определение количества переданных в расширенную хранимую
процедуру параметров */
if (srv_rpcparams(pSrvProc) != 1)
{
printError(pSrvProc, "Не верное количество параметров!");
return (XP_ERROR);
}
/* Получение информации о типе данных и длине переданых параметров */
if (srv_paraminfo(pSrvProc, 1, &bType, &cbMaxLen,
&cbActualLen, NULL, &fNull) == FAIL)
{
printError (pSrvProc,
"Не удаётся получить информацию о входных параметрах...");
return (XP_ERROR);
}
/* Проверяем, является ли переданный параметр OUTPUT параметром */
if ((srv_paramstatus(pSrvProc, 1) & SRV_PARAMRETURN) == FAIL)
{
printError (pSrvProc,
"Переданный параметр не является OUTPUT параметром!");
return (XP_ERROR);
}
/* Проверяем тип данных переданного параметра */
if (bType != SRVBIGVARCHAR && bType != SRVBIGCHAR)
{
printError (pSrvProc, "Не верный тип переданного параметра!");
return (XP_ERROR);
}
/* Убедимся, что переданный параметр имеет достаточную длину для сохранения возвращаемой строки */
if (cbMaxLen < strlen(szText))
{
printError (pSrvProc,
"Передан параметр не достаточной длины для сохранения n возвращаемой строки!");
return (XP_ERROR);
}
/* Устаналиваем значение OUTPUT параметра */
if (FAIL == srv_paramsetoutput(pSrvProc, 1, (BYTE*)szText, 13, FALSE))
{
printError (pSrvProc,
"Не могу установить значение OUTPUT параметра...");
return (XP_ERROR);
}
srv_senddone(pSrvProc, (SRV_DONE_COUNT | SRV_DONE_MORE), 0, 1);
return (XP_NOERROR);
}
void printError (SRV_PROC *pSrvProc, CHAR* szErrorMsg)
{
srv_sendmsg(pSrvProc, SRV_MSG_ERROR, XP_HELLO_ERROR, SRV_INFO, 1,
NULL, 0, 0, szErrorMsg,SRV_NULLTERM);
Srv_senddone(pSrvProc, (SRV_DONE_ERROR | SRV_DONE_MORE), 0, 0);
}
Не рассмотренными остались функции srv_sendmsg и srv_senddone. Функция srv_sendmsg используется для посылки сообщений клиенту. Вот её прототип:
int srv_sendmsg (
SRV_PROC * srvproc,
int msgtype,
DBINT msgnum,
DBTINYINT class,
DBTINYINT state,
DBCHAR * rpcname,
int rpcnamelen,
DBUSMALLINT linenum,
DBCHAR * message,
int msglen
);
В процессе работы расширенная хранимая процедура должна регулярно сообщать клиентскому приложению свой статус, т.е. посылать сообщения о выполненных действиях. Для этого и предназначена функция srv_senddone:
int srv_senddone (
SRV_PROC * srvproc,
DBUSMALLINT status,
DBUSMALLINT info,
DBINT count
);
status статус флаг. Значение этого параметра можно задавать использую логические операторы AND и OR для комбинирования констант приведённых в таблице:
Status flag Описание
SRV_DONE_FINAL Текущий набор результатов является окончательным;
SRV_DONE_MORE Текущий набор результатов не является окончательным следует ожидать очердную порцию данных;
SRV_DONE_COUNT Параметр count содержит верное значение
SRV_DONE_ERROR Используется для уведомления о возникновении ошибок и немедленном завершении.
into
зарезервирован, необходимо установить в 0.
count количество результирующих наборов данных посылаемых клиенту. Если флаг status установлен в SRV_DONE_COUNT, то count должен содержать правильное количество посылаемый клиенту наборв записей.
Возвращаемыме значения:
- в случае успеха SUCCEED
- при неудаче FAIL.
Установка расширенных хранимых процедур на MS SQL Server 2000
1.Скопируйте dll библиотеку с расширенной хранимой процедурой в каталог binn на машине с установленным MS SQL Server. У меня этот путь следующий: C:Program FilesMicrosoft SQL ServerMSSQLBinn;
2.Зарегистрирйте расширенную хранимую процедуру на серверt выполнив следующий скрипт:
USE Master
EXECUTE SP_ADDEXTENDEDPROC xp_helloworld, xp_helloworld.dll
Протестируйте работу xp_helloworld, выполнив такой скрипт:
DECLARE @Param varchar(33)
EXECUTE xp_helloworld @Param OUTPUT
SELECT @Param AS OUTPUT_Param
Заключение
На этом первая часть моей статьи закончена. Теперь я уверен Вы готовы справиться с нашим техническим заданием на все 100%. В следующей статье Вы узнаете:
- Типы данных определённые в ODS API;
- Особенности отладки расширенных хранимых процдур;
- Как формировать recordset-ы и передавать их клиентскому приложению;
- Чстично мы рассмотрим функции Active Directory Network Manegment API необходимые для получения списка доменных пользователей;
- Создадим готовый проект (реализуем наше техническое задание)
Надеюсь - до скорой встречи!
PS: файлы примера для статьи качать для студии 7.0
Каждый современный человек владеет ноутбуком, но как самому убрать возникающие...

На сегодняшний день ценность внутриигровых вещей в Counter-Strike: Global...

Статьи и ЛайфхакиВопрос о том, как установить дату и время на Nokia , волнует...